Google-Wide Profiling: A Continuous Profiling Infrastructure for Data Centers 论文介绍了 Google 内部的 Profilling 系统,简称 GWP。GWP 能够持续地对跨数据中心的基础设施进行 profilling,获取包括了栈调用,硬件事件,堆 profile,内核事件等等信息,并进行后续的数据分析。受这篇论文影响,Conprof 是一个对应用程序进行持续 profilling 的系统。虽然目前还不算成熟,Conprof 已经在我们组生产环境的集群上稳定运行了几个月了,并且能在 debug 线上集群问题方面提供非常大的帮助。
据我所知,Conprof 最早亮相于 KubeCon EU 2019 的 Keynote 演讲上。Conprof 的主要作者 Frederic 和 Grafana 的 VP Tom 分享了 Observability 的未来趋势,当时他们预测了三点。很有趣的是,2020 年底这个时间节点回过头来看,这三点基本已经成为现实:
- More correlation between the three pillars (monitoring, logging and tracing)
- New signals and new analysis
- Rise of index free log aggregation
先来聊聊第三点。Index free log aggregation 的服务,在这里主要指的是 Grafana Loki。以往我们在日志的解决方案上通常采用 EFK 来收集、索引以及查询日志,但是这真的有必要吗?很多时候我们并不需要建立那么多的索引,我们只需要类似 grep 那样的功能来对日志进行查询。
就这有了 Loki,它并不像 ES 一样需要你自己管理索引,而是采用 Prometheus 一样的 labels 机制来索引日志数据。这样的机制非常适合在云原生的场景下进行使用,在 Kubernetes 中,日志通常是以 Cluster, Namespace 以及 Pod 的维度进行收集和查询,在大多数情况下通过这几个简单的标签我们就可以找到对应的容器,并通过内容过滤查询日志。每个 Pod 的监控指标和日志被相同的 labels 元数据信息给串联了起来,这也为后面实现多种可观察性指标的互相关联打下了基础。
再来说第一点,打通可观察性目前也是很多公司正在做的工作,包括了 Grafana,Chronosphere (M3DB 背后的公司) 以及我司。在日前结束的 ObservabilityCon 上, Grafana 演示了一个 demo 来展示他们如何打通 metrics,logs,traces。首先在查询 Loki 的日志,对于使用了 tracing 库的 HTTP 请求,每个请求都会带上一个 traceID,并且这些 ID 会被打印在日志中。通过 traceID 可以定位到一个唯一的 trace, 从而跳转到 trace 系统的 UI 进行查询。
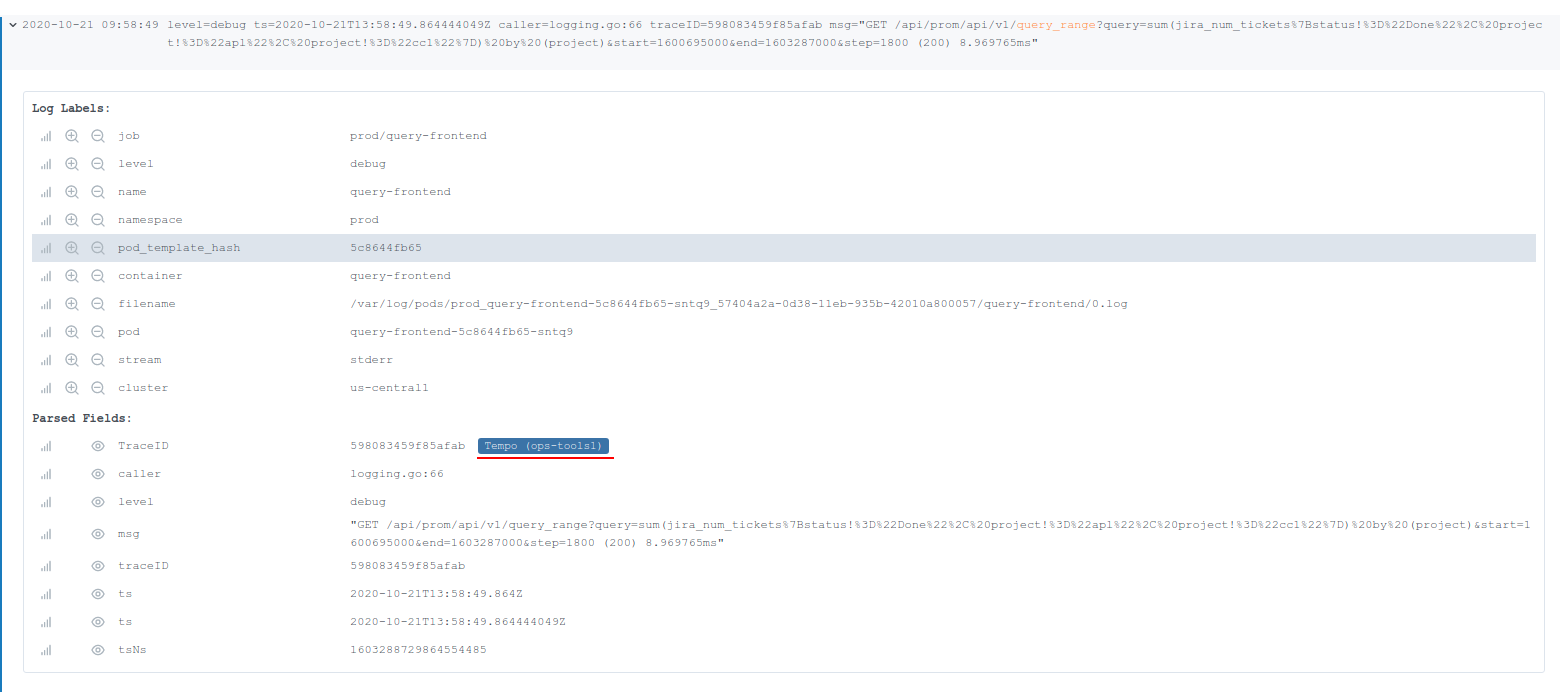
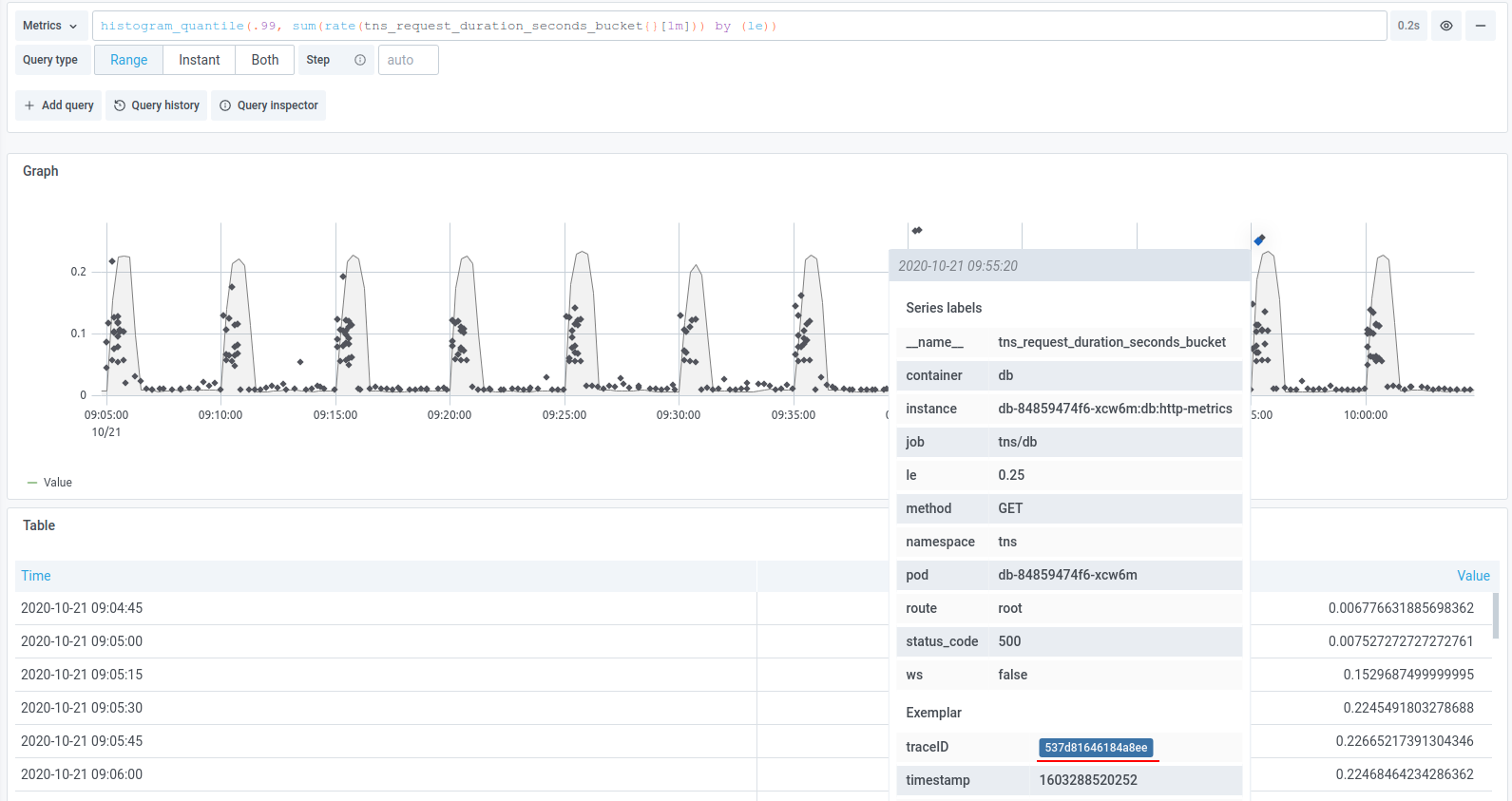
在 metrics 与 trace 的结合上,主要是采用 exemplars 的机制在 metrics 中带上额外的信息。 Exemplar 最早被用在 Google 的 StackDriver 中,后面成为了 OpenMetrics 标准的一部分,在应用通过标准 /metrics 端口暴露 metrics 时,exemplar 信息也会被一起暴露。对于 Prometheus 来说,在写路径上,Prometheus 收集 metrics 的时候也会一并收集 exemplars 信息,并存储下来。在读路径上,会通过一个单独的 API 来暴露 exemplars 信息。
$ curl -g 'http://localhost:9090/api/v1/query_exemplar?query=test_exemplar_metric_total&start=2020-09-14T15:22:25.479Z&end=020-09-14T15:23:25.479Z'
{
"status": "success",
"data": [
{
"seriesLabels": {
"__name__": "test_exemplar_metric_total",
"instance": "localhost:8090",
"job": "prometheus",
"service": "bar"
},
"exemplars": [
{
"labels": {
"traceID": "EpTxMJ40fUus7aGY"
},
"value": 6,
"timestamp": 1600096945479,
"hasTimestamp": true
}
]
},
]
}
借用这种机制,我们可以把 trace ID 作为一个 label pair 加入 exemplar 中,从而可以从 Prometheus 中查询到 trace 的信息,从而将 metrics 和 trace 连接起来。当然,目前这个功能还并没有合并进 master,如果对 exemplar 有兴趣可以看看这个 PR 。
Continous Profilling
好的,感觉扯的有点远了。最后讲讲今天的主题,第二点中的 new signals,指的就是 profiles。
Profiles 目前已经被广泛运用,例如开源的 pprof 已经是 Go 标准库的一部分; 其他语言也有 pprof 的实现,例如 Rust 的pprof-rs 。Profiles 可以帮助我们分析,观察程序的运行性能,包括 CPU,内存 (heap),goroutine 等等。
与 metrics 类似,pprof 也是通过 HTTP 端点进行暴露。那么如果像 Prometheus 一样,每隔一段时间定期去抓取程序的 profiles 并存储在 TSDB 中,后续出现问题了再去查询那个时间段的 profiles,就能够很方便地定位到问题,其实这就是 Conprof。
Conprof 本质上是和 Prometheus 一样的系统,它可以通过一个二进制文件直接运行。不过为了更好的可扩展性,它也支持微服务模式来更好的支持横向扩展。它将内部的组件分成了三个部分,组件之间通过 gRPC 进行通信。主要的组件包括:
- Sampler
- Store
- API
Sampler 是数据的写入部分,它基于 Pull 模型,直接使用了 Prometheus 的服务发现模块来发现 targets,定期对他们进行 Profiling,并将结果的 protobuf 压缩后,通过gRPC API 写入到 Store 中。
Store 就是一个 gRPC API 封装起来的 TSDB。Conprof 的 TSDB 是一个 fork 版本的 Prometheus TSDB。它与上游的 TSDB 基本一样,唯一的区别就是 Conprof 中存储的是 protobuf,sample 的值类型是 []byte, 而 Prometheus sample 的值是 float64。这导致了 Prometheus 中的数据可以使用 Gorilla paper 中的方式对样本进行 delta-xor 压缩,而 Conprof 不行,所以在内存和磁盘使用量上目前还是会高于 Prometheus。
最后是 API 也就是 Query 组件。它对外暴露了类似于 Prometheus 的 API,包括 query, label_names, label_values, series 等等。另外它也包括一个非常简单的 web UI 来查询 profiles,比如下图中蓝色的小点代表了每一个 profile 的采样,单击一下就可以看到对应的 pprof UI。
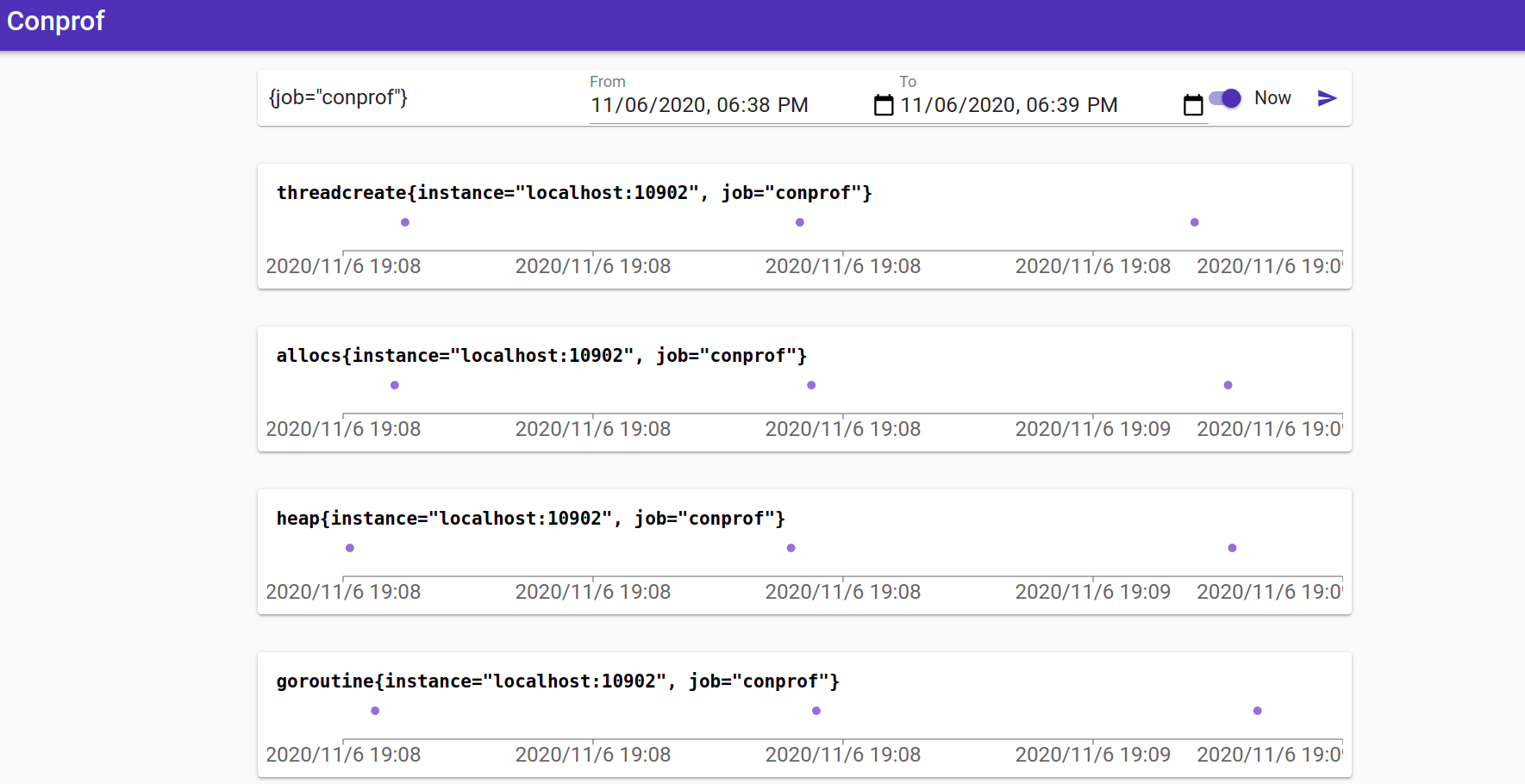
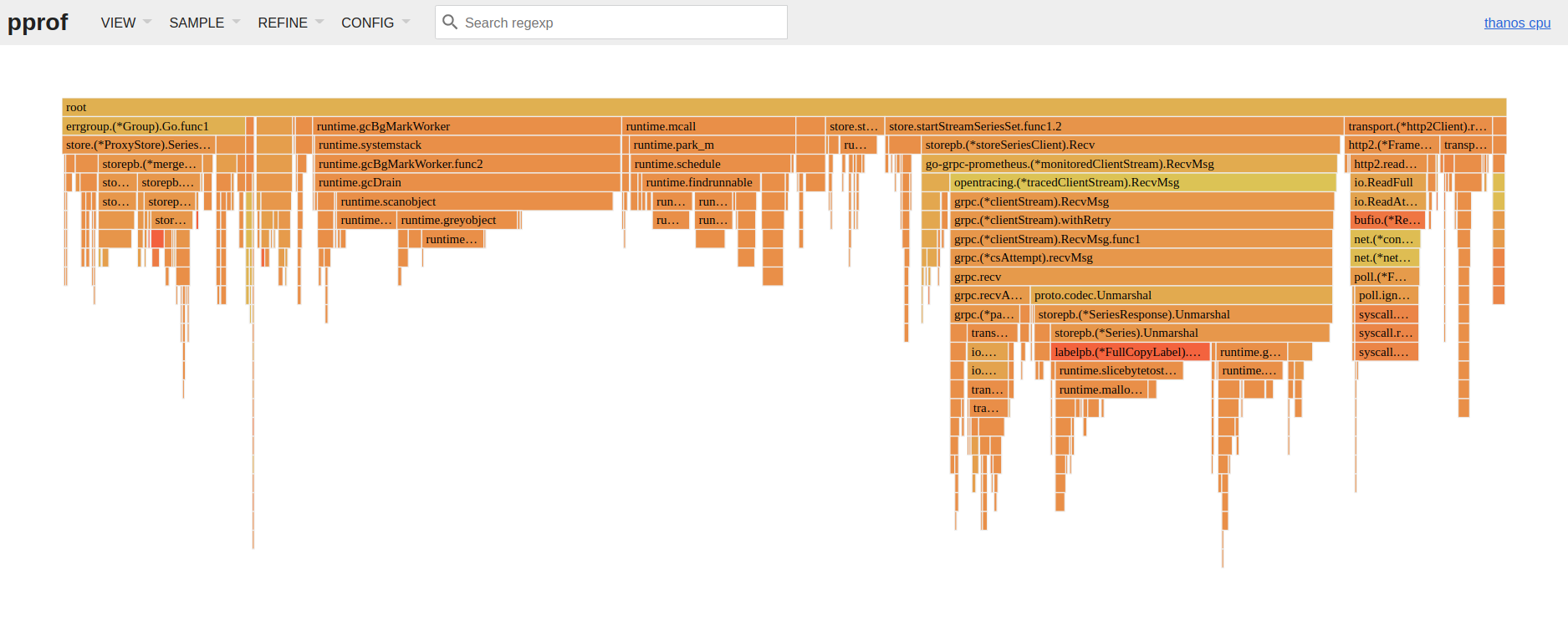
不过目前来说这个 UI 来处于非常初级的阶段,而且暂时没办法与其他指标进行集成。如果想要将 Conprof 与 Grafana 更好的集成,可以看看这个为 Grafana 实现的 Conprof 数据源,用来在 Grafana上通过 annotations 来展示 profiles https://github.com/yeya24/conprof-datasource 。
未来?
更灵活的查询
目前来说,Conprof 虽然已经能够收集 profiles,但是仅仅做到这一点显然是不够的。对用户来说,UI 还不太好用,查询的 API 也不够灵活。现在的查询 API 除了返回基本的元信息,只能返回 pprof 的 proto 文件,而无法直接查询到例如某个时间的 goroutine 总数,某个函数的调用时间等等比较具体的值。
数据分析
Profilling 和 Tracing 系统其实很类似。我们可以使用 profile 和 trace 数据来进行问题的定位,但是我们能否从这些数据中获取更有价值的信息? 分布式追踪系统中的 Jaeger 项目在目前出现了 OpenTelemetry 之后,目前也把重心放到了分析方向,对 Jaeger 加入 Jupyter Notebook,Spark 等多种系统的支持。同样我感觉这也是 Conprof 的发展方向。
集成 metrics, traces, logs
进行这方面的集成可以有两种思路:
- 基于 Grafana 这个平台,开发给 pprof 的 panel 插件,这样可以直接展示出 profiles。由于 Conprof 也是基于 labels 的系统,所以可以和 Prometheus, Loki 等系统进行联动。
- 基于 Exemplars,前面提到了 Exemplars 包含了标签对,也就是说我们只需要将单独一个类似于 ID 一样的东西来唯一标识一个 profile, 然后通过 Exemplar 来将 metrics 链接到对应的 profile。
联系作者
由于本人水平有限,有错误欢迎大家指出。如果你对于Observability感兴趣,或者是你觉得这篇文章对你有帮助,你都可以联系我。我的微信是 eWJfeGExNAo=,你也可以在 Github 上找到我。